

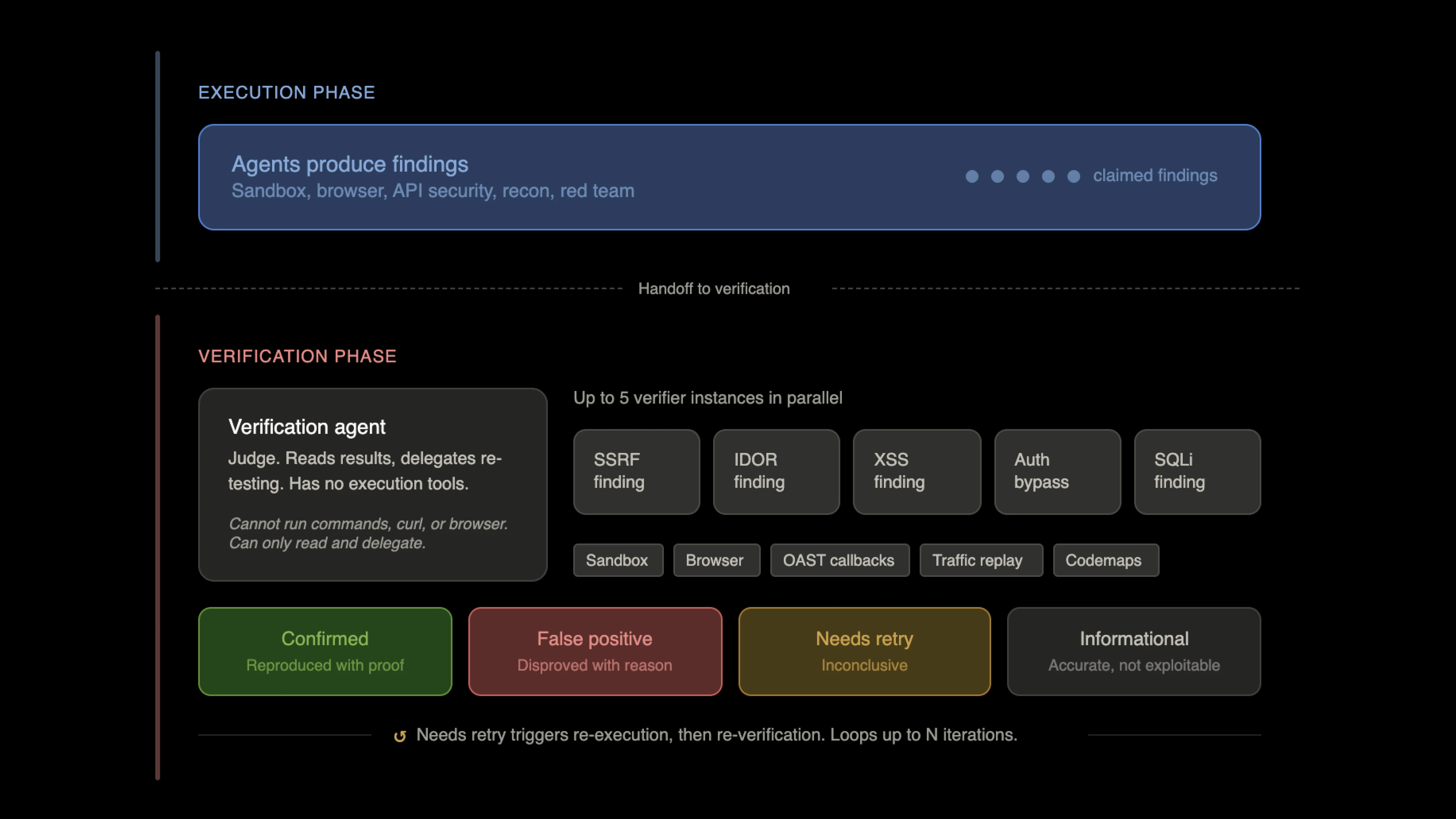
How the critique system works
Neo separates the agent that finds vulnerabilities from the agents that prove them. After execution completes, a dedicated verification agent reviews every claimed finding. This agent has no execution tools. It cannot run commands, make HTTP requests, or interact with browsers. It can only read sandbox artifacts, inspect working memory, and evaluate claims. Its sole job is to act as a judge. For each finding, the verification agent delegates to a verifier agent instance. Each verifier independently attempts to reproduce the vulnerability through its own testing. Up to five verifier instances run in parallel, so a batch of findings does not go through sequential validation. The verifier’s default position is that every finding is a false positive. It has to be convinced otherwise through its own evidence. This adversarial stance is deliberate. The agent that found the issue is not the agent that confirms it. Two independent agents must agree before anything gets reported.Structured verdicts
Each verifier returns one of four verdicts. Confirmed means the verifier independently reproduced the vulnerability with its own evidence. False positive means the verifier could not reproduce it and determined the original finding was incorrect, with a documented reason. Needs retry means the verifier could not conclusively prove or disprove the finding, typically due to environmental issues like rate limiting or authentication problems. Informational means the finding is technically accurate but does not represent an exploitable vulnerability in context. These are not confidence scores or probability estimates. They are binary outcomes backed by evidence. A finding is either proven or it is not.What the verifier has access to
The verifier agent has the full execution toolkit available for re-testing. This includes sandbox commands for arbitrary shell execution, browser automation via Playwright for DOM-based and client-side testing, the web test toolkit for SSRF canaries, XSS payloads, DNS rebinding, out-of-band callbacks, redirect chains, XXE payloads, and polyglot file generation. It also has access to OAST (out-of-band application security testing) through Interactsh. This is critical for blind vulnerability classes where the exploit does not produce a visible response. The verifier registers callback domains, injects payloads, and polls for interactions to confirm blind injection, blind SSRF, and blind XXE. Traffic replay allows the verifier to take HTTP requests captured during the execution phase and replay them with modified parameters, exploit payloads, or different authentication contexts. This is particularly useful for re-testing API endpoints where the original execution agent discovered interesting behavior. For confirmed findings, the verifier produces proof artifacts: standalone PoC scripts saved to the sandbox, source-to-sink traces when code is available, bypass examples, screenshots, and callback evidence. These artifacts attach to the issue so the finding arrives with reproducible proof, not just a claim.Gray-box verification
When the target’s source code is indexed, the verifier gains gray-box capabilities through codemaps and knowledge search. Codemaps provide structural analysis of the codebase: module trees, dependency graphs, entry points, and per-module criticality scoring. Knowledge search enables semantic queries across the indexed code. This lets the verifier trace whether attacker-controlled input actually reaches a dangerous sink, whether framework protections block the exploit path, whether authentication middleware intercepts the request before it hits the vulnerable handler, and whether guards are sufficient or bypassable. The verifier can review the actual authorization logic, find all callers of a dangerous function, and confirm whether a vulnerability is exploitable in the context of the full application. This is the difference between flaggingeval(userInput) as dangerous and confirming that userInput comes from an unauthenticated HTTP parameter, passes through no sanitization, and reaches eval on a public route.
Automated verification services
Beyond the agent-driven verification, Neo has dedicated automated verification services that run independently. A Playwright-based vulnerability verifier tests XSS and open redirect findings through real browser automation. For XSS, it injects payloads with validation tokens into the target URL and checks whether the token appears in browser dialogs or console output. For open redirects, it tests whether the URL actually redirects to an attacker-controlled domain. This provides browser-level confirmation that is independent of the agent’s judgment. An XSS context analyzer examines where user input reflects in HTML responses. It identifies the injection context (HTML body, script block, attribute value, or comment) and analyzes whether the context allows exploitation. A reflection inside a quoted attribute requires a different exploit path than a reflection inside a script tag. The analyzer maps these contexts so the verifier can target the right payload.Proof-based gating for code reviews
GitHub PR reviews use a separate, structured evidence framework. Every finding must pass through six proof dimensions before it can be posted as a review comment. Attacker control confirms that the input source is actually controllable by an attacker. Reachability confirms the vulnerable code path is reachable from an entry point, and that the surrounding middleware and route registration were reviewed. Dangerous sink confirms the data reaches a function or operation that is dangerous in context. Guard effectiveness checks whether application-level guards (input validation, sanitization, allowlists) block the exploit. Framework protection checks whether the framework itself provides built-in protections (auto-escaping, CSRF tokens, parameterized queries). Impact confirms a concrete attacker outcome. Each dimension resolves to one of four states: proven, blocked, insufficient, or unknown. If any required dimension is blocked, the finding is dropped. If any dimension has insufficient proof, the finding is dropped. The system also requires proof artifacts specific to the vulnerability category. Injection and XSS findings need a source-to-sink trace and sink call. Auth and access control findings need a bypass path. SSRF and open redirect findings need a bypass example. High-severity findings and categories like auth, access control, SSRF, RCE, and deserialization trigger deep verification, which requires all six dimensions to be fully proven with no unknowns. Findings on authenticated endpoints must include auth bypass evidence or they are dropped. This is a programmatic gate, not an LLM judgment call. The evidence framework evaluates structured data against deterministic rules. A finding either meets the proof requirements or it does not.The iteration loop
Verification operates as a loop, not a single pass. After the initial execution completes, the verification agent reviews the results. If the verdict indicates that execution needs to be re-run (incomplete coverage, missed areas, or findings that need a different approach), the orchestrator triggers another execution pass with specific guidance. The re-execution pass reads the previous verifier’s log at/workspace/verification/iteration-N.md in the sandbox. It knows what was tried, what failed, and what should be approached differently. Working memory tracks which findings are confirmed, which are false positives, and which need retry. Each cycle builds on the last rather than repeating work.
This loop continues up to a configurable maximum number of iterations, ensuring the system converges toward a complete and accurate set of results.